 Semantic portal
Semantic portal
Unicode
Unicode is a computing industry standard designed to consistently and uniquely encode characters used in written languages throughout the world. The Unicode standard uses hexadecimal to express a character. For example, the value 0x0041 represents the Latin character A. The Unicode standard was initially designed using 16 bits to encode characters because the primary machines were 16-bit PCs.
When the specification for the Java language was created, the Unicode standard was accepted and the char primitive was defined as a 16-bit data type, with characters in the hexadecimal range from 0x0000 to 0xFFFF.
Because 16-bit encoding supports 216 (65,536) characters, which is insufficient to define all characters in use throughout the world, the Unicode standard was extended to 0x10FFFF, which supports over one million characters. The definition of a character in the Java programming language could not be changed from 16 bits to 32 bits without causing millions of Java applications to no longer run properly. To correct the definition, a scheme was developed to handle characters that could not be encoded in 16 bits.
The characters with values that are outside of the 16-bit range, and within the range from 0x10000 to 0x10FFFF, are called supplementary characters and are defined as a pair of char values.
Terminology
A character is a minimal unit of text that has semantic value.
A character set is a collection of characters that might be used by multiple languages. For example, the Latin character set is used by English and most European languages, though the Greek character set is used only by the Greek language.
A coded character set is a character set where each character is assigned a unique number.
A code point is a value that can be used in a coded character set. A code point is a 32-bit int data type, where the lower 21 bits represent a valid code point value and the upper 11 bits are 0.
A Unicode code unit is a 16-bit char value. For example, imagine a String that contains the letters "abc" followed by the Deseret LONG I, which is represented with two charvalues. That string contains four characters, four code points, but five code units.
To express a character in Unicode, the hexadecimal value is prefixed with the string U+. The valid code point range for the Unicode standard is U+0000 to U+10FFFF, inclusive. The code point value for the Latin character A is U+0041. The character € which represents the Euro currency, has the code point value U+20AC. The first letter in the Deseret alphabet, the LONG I, has the code point value U+10400.
The following table shows code point values for several characters:
| Character | Unicode Code Point | Glyph |
|---|---|---|
| Latin A | U+0041 |
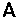 |
| Latin sharp S | U+00DF |
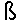 |
| Han for East | U+6771 |
 |
| Deseret, LONG I | U+10400 |
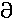 |
As previously described, characters that are in the range U+10000 to U+10FFFF are called supplementary characters. The set of characters from U+0000 to U+FFFF are sometimes referred to as the Basic Multilingual Plane (BMP).
More terminology can be found in the Glossary of Unicode Terms, listed on the More Information page.
Supplementary Characters as Surrogates
To support supplementary characters without changing the char primitive data type and causing incompatibility with previous Java programs, supplementary characters are defined by a pair of code point values that are called surrogates. The first code point is from the high surrogates range of U+D800 to U+DBFF, and the second code point is from the low surrogates range of U+DC00 to U+DFFF. For example, the Deseret character LONG I, U+10400, is defined with this pair of surrogate values: U+D801 and U+DC00.
Character and String APIs
The Character class encapsulates the char data type. For the J2SE release 5, many methods were added to the Character class to support supplementary characters. This API falls into two categories: methods that convert between char and code point values and methods that verifiy the validity of or map code points.
This section describes a subset of the available methods in the Character class. For the complete list of available APIs, see the Character class specification.
Conversion Methods and the Character Class
The following table includes the most useful conversion methods, or methods that facilitate conversion, in the Character class. The codePointAt and codePointBeforemethods are included in this list because text is generally found in a sequence, such as a String, and these methods can be used to extract the desired substring.
| Method(s) | Description |
|---|---|
toChars(int codePoint, char[] dst, int dstIndex)toChars(int codePoint) |
Converts the specified Unicode code point to its UTF-16 representation and places it in a char array. Sample usage: Character.toChars(0x10400) |
toCodePoint(char high, char low)toCodePoint(CharSequence, int)toCodePoint(char[], int, int) |
Converts the specified parameters to its supplementary code point value. The different methods accept different input formats. |
codePointAt(char[] a, int index)codePointAt(char[] a, int index, int limit)codePointAt(CharSequence seq, int index) |
Returns the Unicode code point at the specified index. The third method takes a CharSequence and the second method enforces an upper limit on the index. |
codePointBefore(char[] a, int index)codePointBefore(char[] a, int index, int start)codePointBefore(CharSequence seq, int index)codePointBefore(char[], int, int) |
Returns the Unicode code point before the specified index. The third method accepts a CharSequence and the other methods accept a char array. The second method enforces a lower limit on the index. |
charCount(int codePoint) |
Returns the value 1 for characters that can be represented by a single char. Returns the value 2 for supplementary characters that require two chars. |
Verification and Mapping Methods in the Character Class
Some of the previous methods that used the char primitive data type, such as isLowerCase(char) and isDigit(char), were supplanted by methods that support supplementary characters, such as isLowerCase(int) and isDigit(int). The previous methods are supported but do not work with supplementary characters. To create a global application and ensure that your code works seamlessly with any language, it is recommended that you use the newer forms of these methods.
Note that, for performance reasons, most methods that accept a code point do not verify the validity of the code point parameter. You can use the isValidCodePoint method for that purpose.
The following table lists some of the verification and mapping methods in the Character class.
| Method(s) | Description |
|---|---|
isValidCodePoint(int codePoint) |
Returns true if the code point is within the range of 0x0000 to 0x10FFFF, inclusive. |
isSupplementaryCodePoint(int codePoint) |
Returns true if the code point is within the range of 0x10000 to 0x10FFFF, inclusive. |
isHighSurrogate(char) |
Returns true if the specified char is within the high surrogate range of \uD800 to \uDBFF, inclusive. |
isLowSurrogate(char) |
Returns true if the specified char is within the low surrogate range of \uDC00 to \uDFFF, inclusive. |
isSurrogatePair(char high, char low) |
Returns true if the specified high and low surrogate code values represent a valid surrogate pair. |
codePointCount(CharSequence, int, int)codePointCount(char[], int, int) |
Returns the number of Unicode code points in the CharSequence, or char array. |
isLowerCase(int)isUpperCase(int) |
Returns true if the specified Unicode code point is a lowercase or uppercase character. |
isDefined(int) |
Returns true if the specified Unicode code point is defined in the Unicode standard. |
isJavaIdentifierStart(char)isJavaIdentifierStart(int) |
Returns true if the specified character or Unicode code point is permissible as the first character in a Java identifier. |
isLetter(int)isDigit(int)isLetterOrDigit(int) |
Returns true if the specified Unicode code point is a letter, a digit, or a letter or digit. |
getDirectionality(int) |
Returns the Unicode directionality property for the given Unicode code point. |
Character.UnicodeBlock.of(int codePoint) |
Returns the object representing the Unicode block that contains the given Unicode code point or returns null if the code point is not a member of a defined block. |
Methods in the String Classes
The String, StringBuffer, and StringBuilder classes also have contructors and methods that work with supplementary characters. The following table lists some of the commonly used methods. For the complete list of available APIs, see the javadoc for the String, StringBuffer, and StringBuilder classes.
Design Considerations
To write code that works seamlessly for any language using any script, there are a few things to keep in mind.
To write code that works seamlessly for any language using any script, there are a few things to keep in mind.
| Consideration | Reason |
|---|---|
Avoid methods that use the char data type. |
Avoid using the char primitive data type or methods that use the char data type, because code that uses that data type does not work for supplementary characters. For methods that take a char type parameter, use the corresponding int method, where available. For example, use the Character.isDigit(int) method rather than Character.isDigit(char) method. |
Use the isValidCodePoint method to verify code point values. |
A code point is defined as an int data type, which allows for values outside of the valid range of code point values from 0x0000 to 0x10FFFF. For performance reasons, the methods that take a code point value as a parameter do not check the validity of the parameter, but you can use the isValidCodePoint method to check the value. |
Use the codePointCount method to count characters. |
The String.length() method returns the number of code units, or 16-bit char values, in the string. If the string contains supplementary characters, the count can be misleading because it will not reflect the true number of code points. To get an accurate count of the number of characters (including supplementary characters), use the codePointCount method. |
Use the String.toUpperCase(int codePoint) and String.toLowerCase(int codePoint)methods rather than the Character.toUpperCase(int codePoint) or Character.toLowerCase(int codePoint) methods. |
While the Character.toUpperCase(int) and Character.toLowerCase(int) methods do work with code point values, there are some characters that cannot be converted on a one-to-one basis. The lowercase German character ß, for example, becomes two characters, SS, when converted to uppercase. Likewise, the small Greek Sigma character is different depending on the position in the string. The Character.toUpperCase(int) and Character.toLowerCase(int) methods cannot handle these types of cases; however, the String.toUpperCase and String.toLowerCase methods handle these cases correctly. |
| Be careful when deleting characters. |
When invoking the StringBuilder.deleteCharAt(int index) or StringBuffer.deleteCharAt(int index)methods where the index points to a supplementary character, only the first half of that character (the first char value) is removed. First, invoke the Character.charCount method on the character to determine if one or two char values must be removed. |
| Be careful when reversing characters in a sequence. |
When invoking the StringBuffer.reverse() or StringBuilder.reverse() methods on text that contains supplementary characters, the high and low surrogate pairs are reversed which results in incorrect and possibly invalid surrogate pairs. |